
[Keras] Prometheus 메트릭 데이터 LSTM 모델로 학습, 예측하기
이전에 Keras 딥러닝 라이브러리 소개와 간단한 시계열 데이터를 학습하고 예측하는 글을 작성했었습니다.
Python Keras 딥러닝 라이브러리 설치 및 시계열 예측 예제(Tensorflow, LSTM)
파이썬 딥러닝 라이브러리 Keras를 알아보자 Keras는 딥러닝 모델을 쉽게 구축하고 훈련할 수 있도록 도와주는 파이썬 라이브러리입니다. TensorFlow, Theano 및 Microsoft Cognitive Toolkit과 같은 다양한 딥
ksr930.tistory.com
이번에는 좀더 심화된 내용으로 클라우드 환경에서 메트릭정보를 수집하는 오픈소스 툴 Prometheus에서 메트릭 데이터를 불러오고 이 데이터로 시계열 모델을 만들어서 학습, 예측하는 방법에 대해 설명하겠습니다.
패키지 설치
Prometheus 데이터 요청과 딥러닝 모델 학습에 필요한 몇가지 패키지 설치를 먼저 진행합니다.
pip install prometheus_api_client
pip install scikit-learn
pip install matplotlib
- prometheus_api_client : Prometheus에 연결하고 promQL 형식으로 메트릭을 요청할수있는 패키지
- scikit-learn : 모델 학습을 위해 학습 데이터를 정규화 하는데 필요한 패키지
- matplotlib : 시계열 데이터를 그래프로 나타내기 위한 패키지
전체 코드
전체 코드를 먼저 실행해보고 자세하게 설명해보겠습니다.
import numpy as np
import pandas as pd
import math
from prometheus_api_client import PrometheusConnect
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from datetime import datetime
import tensorflow as tf
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import LSTM, Dense
import matplotlib.pyplot as plt
# Connect to Prometheus server
prom = PrometheusConnect(url='http://100.100.106.150:31710')
tf.random.set_seed(7)
# Define query parameters
step = '5m'
query = 'irate(node_vmstat_pgfault{instance="100.100.106.153:9100",job="node-exporter"}[5m])'
start_time = datetime(2023, 3, 6, 3, 0, 0)
end_time = datetime(2023, 3, 6, 15, 0, 0)
# Retrieve raw data from Prometheus
raw_data = prom.custom_query_range(query=query, start_time=start_time, end_time=end_time, step=step)
# convert an array of values into a dataset matrix
def create_dataset(train_data, look_back=1):
dataX, dataY = [], []
for i in range(len(train_data) - look_back - 1):
a = train_data[i:(i + look_back), 0]
dataX.append(a)
dataY.append(train_data[i + look_back, 0])
return np.array(dataX), np.array(dataY)
# 메트릭 데이터 DataFrame 으로 변경
dataset = pd.DataFrame(raw_data[0]['values'], columns=['timestamp', 'value'])
# timestamp 규격 변경
dataset['timestamp'] = pd.to_datetime(dataset['timestamp'], unit='s')
dataset['value'] = dataset['value'].astype(float)
dataset['value'] = dataset['value'].round(4)
dataset.set_index('timestamp', inplace=True)
# 데이터 정규화
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
# 67%는 학습용 데이터, 나머지는 테스트 생성
train_size = int(len(dataset) * 0.67)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size, :], dataset[train_size:len(dataset), :]
# reshape into X=t and Y=t+1
look_back = 1
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
# 3차원 입력 데이터 생성 [samples, time steps, features]
trainX = np.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
testX = np.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
# LSTM 모델 구성
model = Sequential()
model.add(LSTM(64, input_shape=(1, look_back)))
model.add(Dense(1))
# 모델 컴파일
model.compile(loss='mse', optimizer='adam')
# 모델 학습
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
# 학습된 모델로 예측하기
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
# 정규화된 데이터를 다시 변환
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform([trainY])
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform([testY])
# 평균제곱오차 계산(LSTM 모델의 성능 측정)
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:, 0]))
print('Train Score: %.2f RMSE' % trainScore)
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:, 0]))
print('Test Score: %.2f RMSE' % testScore)
# 학습용 데이터 plot
trainPredictPlot = np.empty_like(dataset)
trainPredictPlot[:, :] = np.nan
trainPredictPlot[look_back:len(trainPredict) + look_back, :] = trainPredict
# 테스트용 데이터 plot
testPredictPlot = np.empty_like(dataset)
testPredictPlot[:, :] = np.nan
testPredictPlot[len(trainPredict) + (look_back * 2) + 1:len(dataset) - 1, :] = testPredict
# plot baseline and predictions
plt.plot(scaler.inverse_transform(dataset))
plt.plot(trainPredictPlot)
plt.plot(testPredictPlot)
plt.show()
결과 로그, 그래프
Epoch 1/100
95/95 - 2s - loss: 0.1985
Epoch 2/100
95/95 - 0s - loss: 0.0777
...
...
...
Epoch 99/100
95/95 - 0s - loss: 0.0496
Epoch 100/100
95/95 - 0s - loss: 0.0505
Train Score: 2701.07 RMSE
Test Score: 2693.36 RMSE
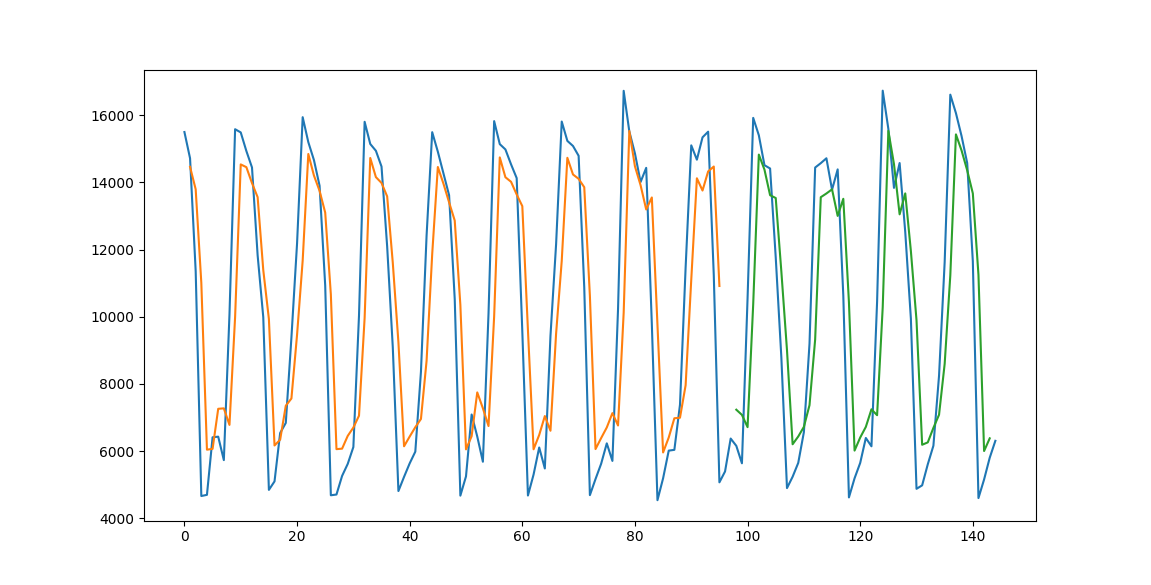
그래프에 파란선이 실제 데이터, 주황색 선은 학습데이터, 초록색 선은 테스트데이터 입니다. 원본데이터와 높은 유사성을 보이는것을 확인할수 있습니다.
소스 코드 분석
Prometheus에서 메트릭 데이터를 불러와서 pandas DataFrame 형태로 변환하고 LSTM 모델을 구성하여 학습하는 부분까지 진행되는 과정의 코드를 단계별로 자세하게 설명해보겠습니다.
1. Prometheus 데이터 요청 및 DataFrame 변환
# 메트릭 데이터 DataFrame 으로 변경
dataset = pd.DataFrame(raw_data[0]['values'], columns=['timestamp', 'value'])
# timestamp 규격 변경
dataset['timestamp'] = pd.to_datetime(dataset['timestamp'], unit='s')
dataset['value'] = dataset['value'].astype(float)
dataset['value'] = dataset['value'].round(4)
dataset.set_index('timestamp', inplace=True)
- Prometheus에 API로 요청한 데이터는
raw_data[0]['values']에 저장되는데 DataFrame으로 변환시 컬럼의 이름은 각각 'timestamp', 'value'로 지정합니다.
dataset.set_index('timestamp', inplace=True)에서 set_index 메서드를 사용해 timestamp 컬럼을 인덱스로 사용하는 이유는 시계열 데이터 분석을 위한 LSTM 모델 구성에서 시간값의 컬럼을 인덱스로 활용하면 LSTM모델이 데이터를 올바르게 해석하고 정확한 예측을 할수있기 때문입니다.
2. 데이터 정규화
# 데이터 정규화
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
- scikit-learn 라이브러리의
MinMaxScaler함수는 데이터를 0에서 1 범위로 정규화하는 데 사용됩니다. - 정규화의 목적은 데이터를 특정 범위(일반적으로 0과 1 또는 -1과 1 사이)로 확장하여 모델이 더 쉽게 패턴을 학습하고 정확한 예측을 할 수 있도록 하는 것입니다.
- 데이터를 정규화하면 큰 입력 값으로 훈련하는 동안 발생할 수 있는 수치적 불안정성을 방지하는데 도움이 됩니다. 전반적으로 정규화는 신경망에서 사용할 데이터를 준비하는 중요한 단계입니다.
3. 학습 데이터, 테스트 데이터 분류
# 67%는 학습용 데이터, 나머지는 테스트 생성
train_size = int(len(dataset) * 0.67)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size, :], dataset[train_size:len(dataset), :]
- 시계열 데이터를 학습 및 예측하기 위해 2/3는 학습데이터, 1/3은 테스트 데이터로 구분합니다. 학습데이터를 기준으로 모델을 학습시키고 테스트 데이터로 모델이 얼마나 학습이 잘 되었는지 예측 할 예정입니다.
4. 학습, 테스트 데이터셋 생성
# convert an array of values into a dataset matrix
def create_dataset(train_data, look_back=1):
dataX, dataY = [], []
for i in range(len(train_data) - look_back - 1):
a = train_data[i:(i + look_back), 0]
dataX.append(a)
dataY.append(train_data[i + look_back, 0])
return np.array(dataX), np.array(dataY)
# reshape into X=t and Y=t+1
look_back = 1
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
- LSTM 모델에서 데이터를 처리하기 위해 DataFrame에서 numpy array로 변형이 필요합니다. 이때
look_back인자는 데이터셋에서 다음 시간 단계의 값을 예측하기 위한 수입니다. - 예를들어 LSTM 모델이 1,2,3,4,5 처럼 1씩 증가하는 데이터셋을 학습하려면 입력데이터 1을 넣을때 출력데이터 2가 나와야 하므로 출력데이터는 데이터셋에서 입력데이터 다음단계의 값이므로 look_back은 1로 설정된 것 입니다.
- trainX, trainY는 각각 학습단계에서 입력, 출력 데이터이고 testX, testY는 각각 테스트에서 입력, 출력 데이터입니다.
5. 입력 데이터 변환
# 3차원 입력 데이터 생성 [samples, time steps, features]
trainX = np.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
testX = np.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
- LSTM에서 학습용 입력 데이터는 3차원 배열의 구조를 가져야 하므로 Numpy 패키지의 reshape 메서드를 이용해 데이터셋을 3차원 배열로 변형해야 하고 각 배열의 차원은
samples, time steps, feature를 뜻합니다. - samples : 모델이 학습하는 데이터셋의 인스턴스 수를 뜻합니다. 위 예제에서는 Prometheus에서 불러온 데이터셋의 2/3에 해당되는 수 입니다.
- time steps : 입력 데이터의 시간 단계 수 입니다.
- feature : 모델이 각 단계에서 받게될 입력 변수의 수를 의미합니다. 여기서는 'value' 값에 대한 데이터만 하므로 1입니다.
6. 모델 구성 및 학습
# LSTM 모델 구성
model = Sequential()
model.add(LSTM(64, input_shape=(1, look_back)))
model.add(Dense(1))
# 모델 컴파일
model.compile(loss='mse', optimizer='adam')
# 모델 학습
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
- 예제에서 모델구성은 64개의 LSTM 레이어와 1개의 Dense 레이어로 구성되있습니다. Dense 레이어는 LSTM 레이어 뒤에 추가되어 예측된 다음 값을 나타내는 단일 출력 값을 생성합니다.
- 모델을 컴파일할때 손실률 계산은 mse(평균오차제곱)을 사용하고 옵티마이저로
adam을 사용하는데adam은 딥 러닝에서 자주 사용되는 최적화 알고리즘 입니다. - 모델 학습에서
epochs는 학습 횟수를 나타냅니다. 학습 횟수가 많을수록 일반적으로 신뢰도는 높아지지만 항상 그런것은 아니며 오히려 너무 많은 학습횟수는 과적합이 발생할수 있습니다.
7. 모델 예측 및 성능측정
# 학습된 모델로 예측하기
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
# 정규화된 데이터를 다시 변환
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform([trainY])
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform([testY])
# 평균제곱오차 계산(LSTM 모델의 성능 측정)
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:, 0]))
print('Train Score: %.2f RMSE' % trainScore)
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:, 0]))
print('Test Score: %.2f RMSE' % testScore)
- 테스트 데이터로 예측을 해보고 예측데이터와 출력데이터의 평균제곱오차(MSE) 값을 계산하여 LSTM 모델의 성능을 측정하는 단계 입니다.
- 예측값 데이터인
trainPredict, testPredict데이터와 출력 데이터인trainY, testY데이터는 정규화된 데이터이므로 원본 데이터와 비교하기 위해 inverse_transform 메서드로 역변환합니다.
8. 그래프 그리기
# 학습용 데이터 plot
trainPredictPlot = np.empty_like(dataset)
trainPredictPlot[:, :] = np.nan
trainPredictPlot[look_back:len(trainPredict) + look_back, :] = trainPredict
# 테스트용 데이터 plot
testPredictPlot = np.empty_like(dataset)
testPredictPlot[:, :] = np.nan
testPredictPlot[len(trainPredict) + (look_back * 2) + 1:len(dataset) - 1, :] = testPredict
# plot baseline and predictions
plt.plot(scaler.inverse_transform(dataset))
plt.plot(trainPredictPlot)
plt.plot(testPredictPlot)
plt.show()
- 원본 데이터와 학습, 테스트 예측 결과를 시각적으로 확인하기 위해 plot을 이용해 그래프를 생성합니다.
- 위의 사진에서 확인했듯이 예측데이터가 원본데이터와 높은 유사성을 보이는 모습을 확인할수 있습니다.
딥러닝 모델 정리
LSTM 모델 뿐만 아니라 모든 딥러닝에서 학습횟수는 중요한 지표입니다. 학습횟수가 단순히 많다고해서 신뢰성이 높아지고 손실률이 줄어드는것은 아닙니다. 학습횟수가 과도하게 많아지면 다른 학습데이터를 받았을때 모델이 제대로 수행되지 않는 과적합이 발생할수 있습니다.
따라서 학습횟수를 조정하면서 테스트를 진행하고 더이상 손실률이 늘어나지 않는 지점을 찾는다면 모델의 학습이 최적화에 도달한것을 알수 있습니다.
'인공지능' 카테고리의 다른 글
| Python Keras 설치와 시계열데이터 활용 방법 (0) | 2023.03.09 |
|---|

댓글