
Python Keras, 딥러닝 라이브러리
Keras는 딥러닝 모델을 쉽게 구축하고 훈련할 수 있도록 도와주는 파이썬 라이브러리입니다. TensorFlow, Theano 및 Microsoft Cognitive Toolkit과 같은 다양한 딥러닝 엔진을 백엔드로 지원합니다.
Keras 기본 특징
- Keras는 간결하고 직관적인 API를 제공하여 사용자가 빠르게 딥러닝 모델을 구축하고 실험할 수 있도록 도와줍니다.
- 일반적으로 순차 모델을 사용하여 구축되는데 레이어를 순서대로 쌓아서 모델을 구성하는 방법입니다. 순차 모델 이외에도 함수형 API를 사용하여 보다 복잡한 모델을 구성할 수도 있습니다.
- 다양한 종류의 레이어, 손실 함수, 최적화 알고리즘 등을 제공하여 사용자가 다양한 딥러닝 모델을 구성할 수 있습니다.
- 이미지 분류, 객체 감지, 텍스트 분류 등과 같은 다양한 딥러닝 태스크를 지원합니다.
머신러닝? 딥러닝?
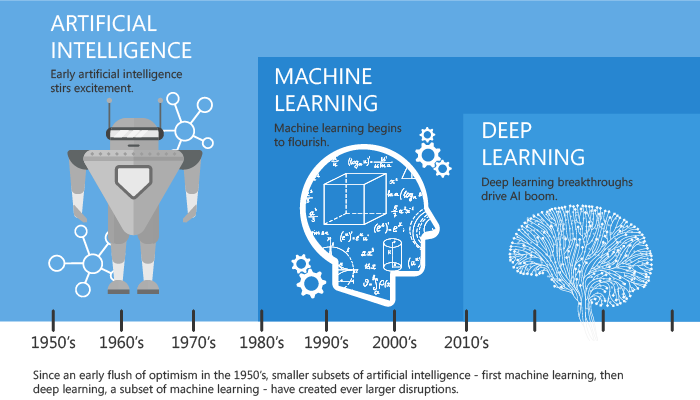
Keras를 배우기전에 우선 머신러닝과 딥러닝이 무엇인지 알아야 이해하기 쉬울것입니다. 머신러닝과 딥러닝의 개념, 머신러닝과 딥러닝은 어떤 차이점이 있는지 알아보겠습니다.
머신러닝(Machine Learning)
머신러닝은 컴퓨터가 데이터를 분석하여 패턴을 파악하고 이를 사용하여 예측을 수행하는 알고리즘
지도학습(supervised learning), 비지도학습(unsupervised learning), 강화학습(reinforcement learning)으로 분류
- 지도학습 : 레이블된 데이터를 사용하여 분류, 회귀 및 기타 예측 모델을 만드는 방법
- 비지도학습 : 레이블 없는 데이터에서 구조를 찾고 클러스터링과 같은 작업을 수행
- 강화학습 : 에이전트가 행동을 수행하고 보상을 받아 보상을 최대화하기 위한 최적의 정책을 찾는 방법
딥러닝(Deep Learning)
- 딥러닝은 머신러닝의 하위 집합으로 인공신경망(artificial neural network)을 사용하여 입력 데이터에서 특징(feature)을 추출하고 이를 기반으로 예측 모델을 구축하는 방법
- 여러 개의 은닉층(hidden layer)을 가진 인공신경망을 사용하기 때문에 더 복잡한 문제를 다룰 수 있음
- 이미지 분류, 음성 인식, 자연어 처리 등의 영역에서 사용
- 머신러닝보다 사람의 개입이 줄어드는대신 더 많은양의 학습데이터가 필요함
모델
- 머신러닝의 개념에서 모델은 입력데이터와 그에대한 출력값 사이의 관계를 나타내는 함수입니다. 모델은 학습 데이터를 사용하여 학습되며, 학습이 완료된 후에는 새로운 입력 데이터에 대한 출력을 생성할 수 있습니다.
- 예를들어 컴퓨터 비전용 모델은 실시간 비디오 속 차량과 보행자를 식별할 수 있고 자연어 처리용 모델은 단어와 문장을 번역할수 있습니다.
머신러닝/딥러닝 차이점
- 가장 큰 차이점은 모델의 복잡성과 데이터셋의 크기입니다. 딥러닝은 머신러닝보다 더 복잡한 모델을 사용하기 때문에 더 많은 데이터가 필요합니다.
- 머신러닝은 작은 데이터셋에서도 잘 작동할 수 있지만, 딥러닝은 수백만 개의 데이터를 필요로 할 수 있습니다. 또한, 머신러닝은 전통적인 머신러닝 알고리즘을 사용하여 데이터를 처리하지만, 딥러닝은 인공신경망을 사용하여 데이터를 처리합니다.
Keras 기본 개념
모델
Keras는 순차 모델과 함수형 API를 모두 지원합니다.
- 순차 모델(Sequential) : 간단한 모델 아키텍처를 만들 때 사용됩니다.
- 함수형 API : 복잡한 모델 아키텍처를 만들 때 사용됩니다.
레이어
레이어는 딥러닝에서 입력, 출력 및 모델의 구조를 결정하는 구성 요소입니다. Keras에서는 다양한 유형의 레이어를 제공하여 다양한 딥러닝 모델을 구성할 수 있습니다.
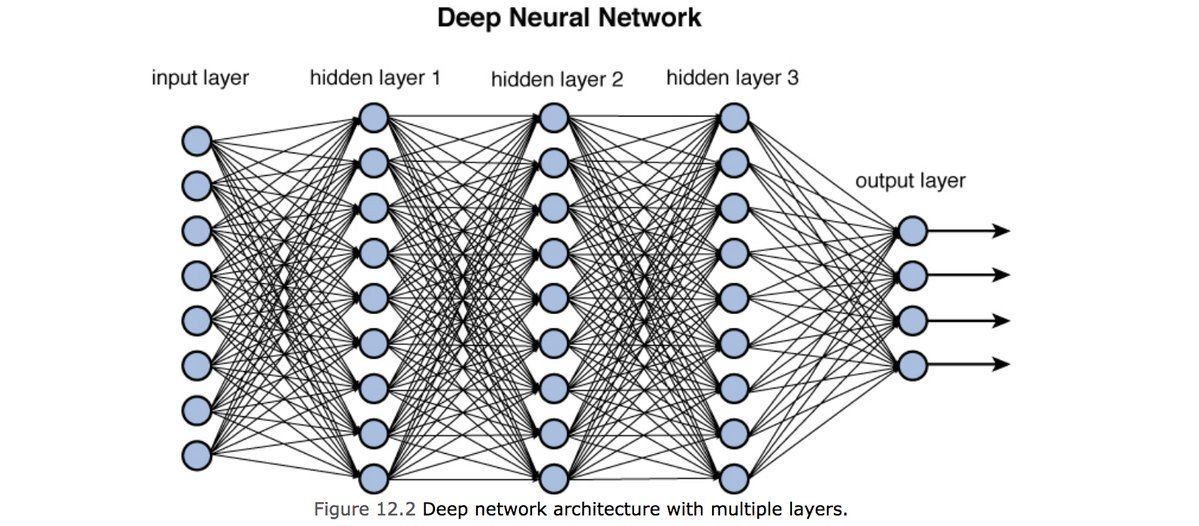
- Dense layer : 이 레이어는 입력과 출력이 완전히 연결된 레이어입니다. 이 레이어는 가중치와 편향을 학습하여 입력과 출력 사이의 선형 관계를 모델링합니다.
- Convolutional layer : 이 레이어는 이미지와 같은 2D 데이터를 처리하는 데 사용됩니다. 컨볼루션 연산을 사용하여 입력과 필터 사이의 특징 맵을 생성합니다. 이를 통해 모델은 이미지와 같은 고차원 데이터의 공간적 정보를 캡처할 수 있습니다.
- Pooling layer : 이 레이어는 2D 데이터의 공간적 차원을 줄이기 위해 사용됩니다. 일반적으로 MaxPooling 또는 AveragePooling이 사용됩니다.
- Recurrent layer : 이 레이어는 순차적인 데이터, 예를 들어 텍스트 또는 시계열 데이터를 처리하는 데 사용됩니다. LSTM, GRU 및 SimpleRNN과 같은 유형의 순환 레이어가 있습니다.
- Embedding layer : 이 레이어는 범주형 데이터, 예를 들어 단어와 같은 텍스트 데이터를 처리하는 데 사용됩니다. 이 레이어는 단어를 고차원 벡터로 매핑하여 모델에 입력합니다.
- Dropout layer : 이 레이어는 과적합을 방지하기 위해 사용됩니다. 이 레이어는 무작위로 선택된 입력 뉴런을 0으로 설정하여 모델의 일반화 능력을 향상시킵니다.
Keras 설치 (TensorFlow)
1. Python 가상환경 생성 및 python 설치
파이썬 패키지를 설치할 때는 항상 가상 환경을 생성하여 설치하는 것이 좋습니다. 이를 통해 패키지 간 충돌을 방지하고, 패키지 관리를 쉽게 할 수 있습니다. 파이썬 패키지 관리 시스템은 Anaconda를 사용했습니다.
(base) conda create -n <가상환경 이름> # 가상 환경 생성(Anaconda)
(base) source <가상환경 이름>/bin/activate # 가상 환경 활성화 (Windows의 경우 conda activate <가상환경 이름>)
가상환경 활성화 이후에 해당 가상환경에 python을 설치합니다. 저는 keras 라는 이름으로 가상환경을 만들었습니다.
(keras) conda install python
가상환경에 대한 자세한 설명은 아래 포스팅을 참고하면 됩니다.
[Python] 파이썬 가상환경 생성하기 (env, anaconda)
[Python] 파이썬 가상환경 만들기 (venv, manaconda) 파이썬의 가상환경 파이썬에서 가상환경은 프로젝트 개발시 사용되는 독립적인 환경입니다. 파이썬으로 개발을 하게되면 여러가지 라이브러리들
ksr930.tistory.com
2. TensorFlow 패키지 설치
Keras를 사용하려면 우선 TensorFlow2 패키지를 설치해야 하고 요구사항은 아래와 같습니다. TensorFlow에 이미 Keras 패키지가 포함되어있으므로 Keras를 따로 설치할 필요는 없습니다.
- Python 3.6 ~ 3.9
- Ubuntu 16.04 이상 or Windows 7 이상
(keras) conda install tensorflow
Keras 간단 예제
IDE는 PyCharm을 사용하였고 인터프리터 설정에서 위에서 생성한 keras 가상환경으로 설정했습니다.
- 연속되는 숫자를 학습데이터로 제공하여 LSTM(시계열) 모델을 구성
- 학습이 완료되고 특정숫자를 제공했을때 학습된 모델이 다음 숫자를 얼마나 정확하게 예측하는가
예제 코드
import numpy as np
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import LSTM, Dense
# 학습 데이터 생성 (입력데이터 X, 결과 데이터 Y)
X = []
Y = []
for i in range(5, 20):
X.append([[j] for j in range(i - 5, i)])
Y.append([i])
X = np.array(X)
Y = np.array(Y)
# LSTM 모델 구성
# LSTM 레이어 50개층, Dense 레이어 1개층으로 구성된 모델
model = Sequential()
model.add(LSTM(50, activation='relu', input_shape=(5, 1)))
model.add(Dense(1, activation='linear'))
model.compile(loss='mse', optimizer='adam')
# 모델 학습, epochs=100 는 100회 학습을 의미한다.
model.fit(X, Y, epochs=100, batch_size=1)
# 다음 값을 예측
next_value = np.array([[[1], [2], [3], [4], [5]]])
predicted_value = model.predict(next_value)
print(f"predict value: {predicted_value[0][0]}")
추가로 코드에 대한 설명이 필요할듯하여 작성해보겠습니다.
- 입력 데이터 X는 3차원 형태로 만드는데 LSTM 모델에서 3차원 데이터를 입력데이터로 사용하는 이유는 1차원부터 3차원까지의 역할이 각각 샘플 수, 스텝 수, 기능 수에 해당합니다. LSTM 모델이 각 샘플의 시간 경과에 따른 일련의 입력 값으로 구성되는 시퀀스 데이터와 함께 작동하도록 설계되었기 때문입니다.
- 입력, 결과 데이터를 np.array로 바꾸는 이유는 python의 기본 list보다 Numpy의 배열이 LSTM 같은 딥러닝 모델에서 대규모 데이터셋을 처리할때 더 효율적이기 때문입니다.
결과
Epoch 1/100
15/15 [==============================] - 2s 2ms/step - loss: 133.5079
Epoch 2/100
15/15 [==============================] - 0s 2ms/step - loss: 95.7050
Epoch 3/100
15/15 [==============================] - 0s 3ms/step - loss: 34.5909
...
...
...
Epoch 98/100
15/15 [==============================] - 0s 3ms/step - loss: 0.0042
Epoch 99/100
15/15 [==============================] - 0s 3ms/step - loss: 0.0063
Epoch 100/100
15/15 [==============================] - 0s 2ms/step - loss: 0.0050
predict value: 6.037531852722168
100회 학습이후에 1,2,3,4,5 다음에 올 숫자를 예측해보니 6이 나오는것을 확인할수있고 손실률을 나타내는 loss 역시 학습 횟수가 증가할수록 줄어드는것을 확인할수 있습니다.
'인공지능' 카테고리의 다른 글
| Python Keras로 Prometheus 메트릭데이터 학습 및 예측하기 (0) | 2023.03.14 |
|---|

댓글