[Kafka] 리밸런싱 오프셋 커밋 subscribe poll 개념 설명
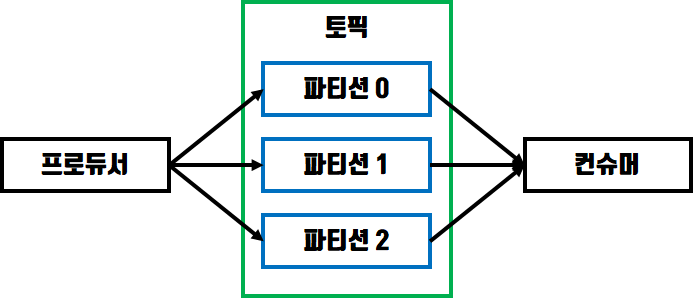
이번에는 Kafka Producer에 이어서 Kafka Consumer 프로그램을 만들어보도록 하겠습니다. 컨슈머의 역할은 프로듀서가 카프카 토픽에 전송한 데이터를 사용하기 위해 가져오는 동작을 수행합니다.
Kafka Consumer 예제
기본 프로젝트 구성은 이전에 Kafka Producer를 만들때와 동일하게 만들고 TestConsumer.java 라는 클래스를 생성하여 다음과 같이 코드를 입력합니다.
IntelliJ 에서 Kafka Producer Client 만들기
[TestConsumer.java]
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
@Slf4j
public class TestConsumer {
private final static String TOPIC_NAME = "ksr-test";
private final static String BROKER_SERVER = "kafka.kafka.svc:9020";
private final static String GROUP_ID = "ksr-group";
public static void main(String[] args) {
Properties conf = new Properties();
conf.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BROKER_SERVER);
conf.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
conf.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
conf.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(conf);
consumer.subscribe(Collections.singletonList(TOPIC_NAME));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records){
log.info("offset : {} key : {} value : {}", record.offset(), record.key(), record.value());
}
}
}
}
컨슈머 그룹
private final static String TOPIC_NAME = "ksr-test";
private final static String BROKER_SERVER = "kafka.kafka.svc:9020";
private final static String GROUP_ID = "ksr-group";
토픽이름과 브로커서버는 Kafka Producer를 만들때도 해봐서 익숙하지만 컨슈머 그룹은 처음들어보는 개념일수도 있습니다.
컨슈머 그룹이란 동일한 목적을 가진 컨슈머끼리 묶어서 사용하기 위한 개념입니다. 컨슈머가 토픽에서 데이터를 읽을때 마지막으로 읽은 위치를 나타내는 컨슈머 오프셋은 컨슈머 그룹별로 관리되기 때문에 subscribe() 메서드를 사용하여 토픽을 구독할때 사용해야 합니다.
역직렬화(Deserializer) 클래스 지정
Properties conf = new Properties();
conf.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BROKER_SERVER);
conf.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
conf.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName();
conf.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
프로듀서에서 레코드를 토픽을 전송할때는 직렬화 클래스를 이용합니다. 반대로 컨슈머에서는 토픽에 저장된
레코드를 사용하기 위해서 역직렬화 클래스인 StringDeserializer 를 사용해야 합니다.
3. 컨슈머 토픽 구독함수 subscribe()
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(conf);
consumer.subscribe(Collections.singletonList(TOPIC_NAME));
KafkaConsumer 인스턴스를 생성하고 컨슈머 옵션인 conf 를 파라미터로 전달하고 컨슈머가 토픽에 저장되는 데이터를 동적으로 가져오기 위한 subscribe 함수를 선언합니다.
레코드 처리 함수 poll()
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records){
log.info("offset : {} key : {} value : {}",
record.offset(), record.key(), record.value());
}
}
컨슈머는 지속적으로 데이터를 가져오기 위해 while로 무한루프를 만들고 poll 함수로 토픽의 데이터를 가져와서 처리합니다. 컨슈머는 poll 함수를 사용할때 마지막으로 소비한 오프셋을 시작 오프셋으로 사용하여 레코드를 순차적으로 가져옵니다.
poll 함수의 파라미터로 사용되는 Duration 은 컨슈머가 해당 시간동안 브로커 서버에서 데이터를 읽어오지 못하면 timeout 을 발생시키고 빈 Collection을 반환하도록 합니다.
이제 가져온 데이터를 확인해보겠습니다.
[main] INFO org.apache.kafka.common.utils.AppInfoParser - Kafka version: 2.8.0
[main] INFO org.apache.kafka.common.utils.AppInfoParser - Kafka commitId: ebb1d6e21cc92130
[main] INFO org.apache.kafka.common.utils.AppInfoParser - Kafka startTimeMs: 1642655552605
[main] INFO org.apache.kafka.clients.consumer.KafkaConsumer - [Consumer clientId=consumer-ksr-group-1, groupId=ksr-group] Subscribed to topic(s): ksr-test
[main] INFO org.apache.kafka.clients.Metadata - [Consumer clientId=consumer-ksr-group-1, groupId=ksr-group] Cluster ID: tfY_mLT6QKmCWp3POZ3yWQ
...
...
...
[main] INFO TestConsumer - offset : 27887 key : null value : a8d6c6b1-9b0b-49dd
[main] INFO TestConsumer - offset : 27911 key : null value : 04a2cde4-0a4f-4c35
[main] INFO TestConsumer - offset : 27888 key : null value : 19d32352-7ccf-48ec
[main] INFO TestConsumer - offset : 27912 key : null value : 830b87a8-4991-46a8
컨슈머 클라이언트를 실행하고 Kafka Consumer의 라이브러리 버전등 초기정보를 출력한다음에 제가 만든 프로듀서에서 데이터를 넣고있는 ksr-test 토픽에서 데이터를 가져와서 처리하는 로그를 볼수있습니다.
Kafka Consumer 중요 개념
컨슈머 그룹
컨슈머 그룹을 사용하면 그룹내의 있는 컨슈머들은 다른 그룹의 컨슈머들과는 독립된 환경에서 데이터를 처리할수 있습니다. 컨슈머 그룹을 사용할때 파티션은 최대 1개의 컨슈머에만 할당이 가능하며 컨슈머는 여러대의 파티션으로부터 데이터를 받을수 있습니다.
즉, 컨슈머그룹내의 컨슈머는 파티션의 개수보다 적거나 같아야 하는 것입니다.
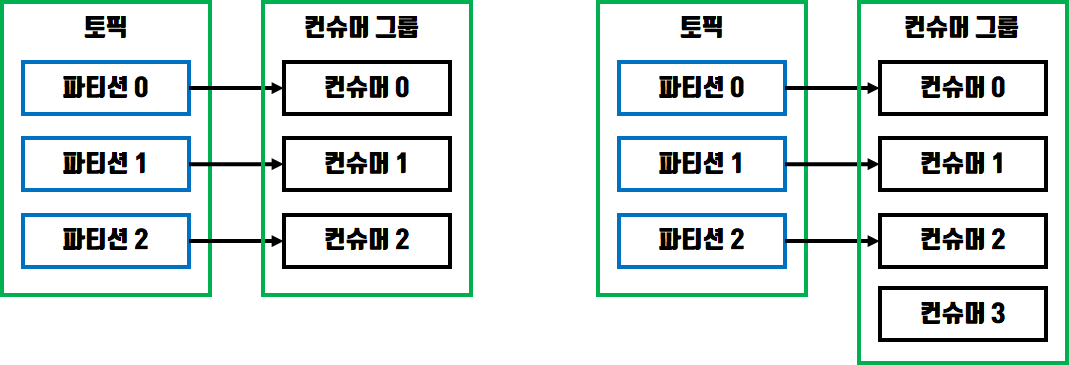
위 그림에서 왼쪽은 파티션과 컨슈머가 1:1로 할당되었지만 오른쪽에서는 파티션의 개수보다 컨슈머의 개수가 많기 때문에 컨슈머 하나가 놀고있게 됩니다.
적재로직 분리
컨슈머 그룹마다 컨슈머 오프셋이 존재하기 때문에 동일한 파티션으로부터 서로 다른 컨슈머 그룹에 있는 컨슈머들은 서로 영향 받지않고 데이터를 처리할수 있습니다.
예를들어 시스템 리소스 데이터를 토픽에 저장하는 프로듀서가 있고 여러개의 컨슈머 그룹을 이용해 각각의 DBMS로 전송하는 컨슈머 클라이언트가 있다고 해보겠습니다.
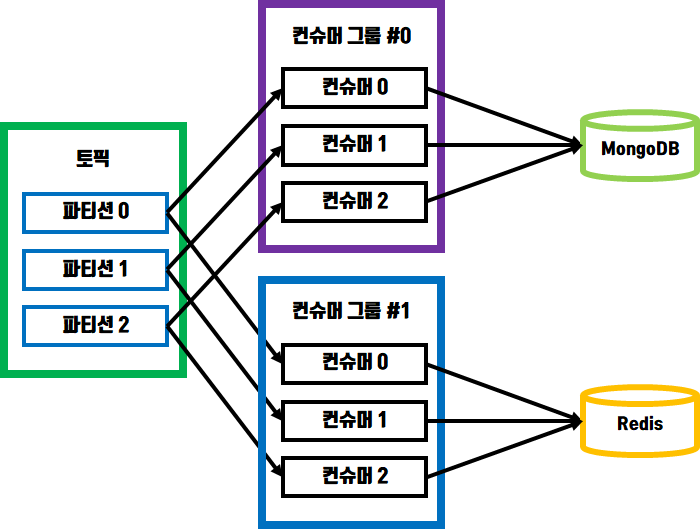
위 환경에서 MongoDB 에 데이터를 전송하는 컨슈머 그룹에 문제가 생겨서 데이터 전송작업이 중단되더라도 해당 컨슈머 그룹이 다시 기동될때 오프셋을 기억하고 있으므로 정상적으로 데이터를 모두 전송할수 있습니다.
리밸런싱
파티션과 컨슈머그룹내의 컨슈머들이 1:1로 매핑되어 데이터를 처리한다고 할때 컨슈머그룹의 특정 컨슈머가 장애를 일으켜서 데이터 처리를 못하게 되면 장애가 발생한 컨슈머와 매핑되있던 파티션은 다른 컨슈머와 매핑되는데 이 과정을 리밸런싱 이라고 합니다.

하지만 리밸런싱이 발생하는 상황을 만들지 않는것이 가장 좋습니다. 리밸런싱이 수행될때 컨슈머 그룹내의 컨슈머들이 파티션으로부터 데이터를 읽지못하게되고 그 시간만큼 데이터 처리 지연이 발생됩니다.
커밋
컨슈머 그룹별로 관리되는 오프셋은 커밋을 통해 기록됩니다. 컨슈머 그룹내의 컨슈머들은 데이터를 poll 함수로 가져올때 일정 간격마다 커밋을 하도록 enable.auto.commit=true 값이 설정되있습니다. 이 옵션은 auto.commit.interval.ms 설정과 같이 사용되는데 poll 함수가 수행되고 해당 시간만큼 시간이 지나면 오프셋을 커밋하게 됩니다.
자동으로 커밋을 하는방법은 코드상으로 따로 명시할 필요가 없어서 편리하지만 컨슈머에서 장애가 발생하거나 리밸런싱을 수행할때 데이터가 유실되거나 중복될 가능성이 있기때문에 안전한 방법은 아닙니다.
그래서 명시적으로 커밋을 하려면 poll 함수의 리턴값을 받을때 commitSync 함수를 호출하면 됩니다. commitSync 함수는 poll 함수를 사용하여 받은 레코드의 가장 마지막 오프셋을 기준으로 수행되는데 브로커 서버에 커밋 요청을 하고 결과를 받기까지 기다리는 시간은 컨슈머 처리속도에 영향을 주게 됩니다.

commitSync 함수를 사용할때 컨슈머의 처리량이 줄어드는것을 방지하기 위해 비동기 방식인 commitAsync 함수를 사용할수 있는데 커밋을 하고 리턴값을 받는 사이에도 데이터를 처리할수는 있지만 커밋 요청이 실패할경우 데이터의 순서를 보장할수없고 중복이 발생할 가능성이 존재합니다.
'Kafka' 카테고리의 다른 글
| 카프카(Kafka) 핵심구조 Pub/Sub, 컨슈머, 프로듀서, 토픽 (0) | 2026.03.04 |
|---|---|
| [Kafka] 오프셋 커밋 동기 비동기, 리밸런스 리스너 (2) | 2022.01.24 |
| Kafka Producer Client 주요 옵션 설명과 메시지 키/특정 파티션/동기-비동기 전송 (0) | 2021.12.02 |
| [Kafka] 카프카의 특징과 내부구조 (브로커, 프로듀서, 컨슈머, 파티션) (0) | 2021.10.27 |
| [Kafka] 카프카 토픽과 파티션, 레코드 저장방식 (0) | 2021.10.27 |




댓글