카프카(Kafka) 내부 구조 - 2
토픽(Topic)
토픽은 데이터를 구분하기 위해 사용하는 단위입니다. RDBMS의 테이블과 같은 개념이기도 합니다.
토픽에는 한개 이상의 파티션이 존재하는데 파티션 내부에는 프로듀서로부터 받은 데이터를
보관하고 있고 카프카에서는 이런 데이터들을 레코드 라고 부릅니다.
토픽은 하나 이상의 파티션을 가질수 있으며 프로듀서에서 받은 레코드를 순서대로 저장합니다.
저장된 레코드는 FIFO 방식으로 컨슈머에서 가져갑니다.
지난번 포스팅에서도 설명했듯이 컨슈머에서 파티션에 있는 레코드를 가져가도 삭제되지 않습니다.
남아있는 레코드는 새로운 컨슈머가 등록되었을때 파티션의 0번 오프셋 레코드부터 순서대로
가져갈수 있습니다.
단, 새로운 컨슈머가 파티션에 있는 레코드를 가져가기 위해서는 몇가지 조건이 있는데
첫번째로 컨슈머 그룹이 달라야 하고 auto.offset.reset = earliest 옵션이 설정되어 있어야 합니다.

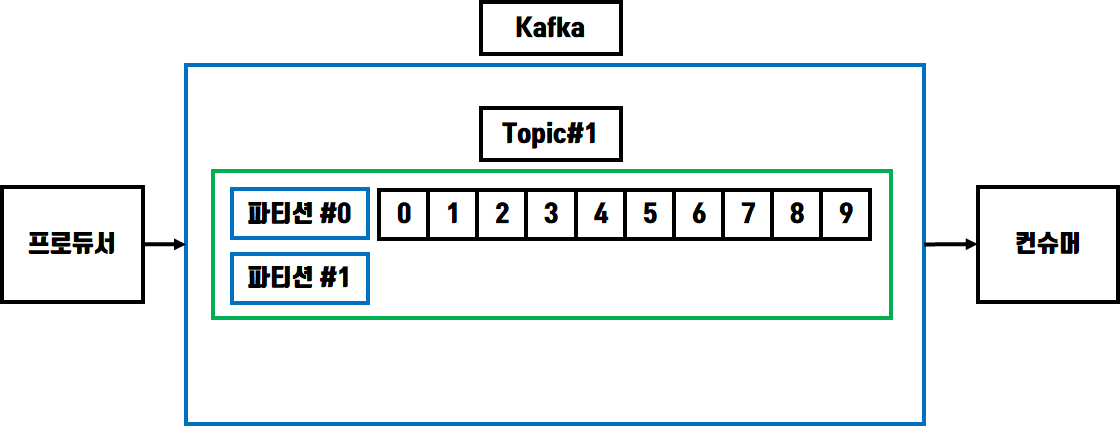
위 그림을 보면 프로듀서 역할을 하는 소스 애플리케이션에서 Topic#1 의 파티션#0 으로
데이터를 전송하여 오프셋 0부터 레코드가 쌓이게 되고 컨슈머 역할을 하는 타겟 애플리케이션은
Topic#1 의 파티션#0 에서 FIFO 방식으로 가장 먼저 저장된 0번 오프셋의 레코드부터 가져가게 됩니다.
토픽의 파티션 저장방식
토픽의 파티션 갯수는 늘릴수 있습니다. 그렇다면 파티션의 갯수가 2개 이상일때 프로듀서는 어느
파티션에 레코드를 저장하게 될까요??
1. 키가 null 일때
라운드 로빈(Round robin) 방식으로 각 파티션에 번갈아가면서 레코드를 저장합니다.

2. 키가 있을때
키의 해쉬값을 구하여 특정 파티션에 저장할수 있습니다.
주의할점
파티션의 갯수를 늘리는것은 가능하지만 반대로 줄일수는 없기 때문에 파티션을 늘리는 것은
신중하게 해야합니다. 또한 파티션에 저장해야할 데이터가 순서를 중요시해야 하는 타입이라면
컨슈머가 순서대로 레코드를 처리하지 않기때문에 라운드로빈 방식으로 데이터가 들어가지 않게
레코드 저장방식을 주의깊게 설정해야 합니다.
파티션의 갯수와 효율성
파티션의 개수가 늘어나면 카프카의 특징인 병렬처리로 인해 효율성이 증가합니다. 하지만 파티션이
많다고 무조건 좋은것은 아닙니다.
파티션이 늘어나는 만큼 관리해야하는 포인트도 증가하게 됩니다. 그래서 파티션은 토픽의 데이터
처리속도가 충분하지 못할경우 늘려야 합니다.
키를 이용하여 파티션에 레코드를 저장시 주의할점
그리고 프로듀서에서 키 값을 지정하여 특정 파티션에 레코드를 저장할때 사용하는 키의 종류가
2개라면 파티션 역시 2개만 존재 해야 합니다.
만약 이상황에서 토픽의 파티션 갯수를 늘린다면 프로듀서의 키와 파티션의 일관성이 맞지않게
되므로 사용자가 의도한대로의 데이터 저장을 보장할수 없게됩니다.
파티션의 레코드 보존기간
파티션에서 저장하고있는 레코드는 컨슈머에서가져가도 삭제되지 않는다고 했습니다.
하지만 레코드가 영원히 삭제되지 않는것은 아니고 파티션에서 레코드의 최대 저장기간 혹은
최대 저장 크기를 설정할수 있습니다.
- log.retention.ms : 레코드 최대 저장 시간
- log.retention.byte : 레코드 최대 저장 크기
'클라우드 > Kafka' 카테고리의 다른 글
| [Kafka] 오프셋 커밋 동기 비동기, 리밸런스 리스너 (2) | 2022.01.24 |
|---|---|
| [Kafka] 리밸런싱 오프셋 커밋 subscribe poll 개념 설명 (0) | 2022.01.21 |
| Kafka Producer Client 주요 옵션 설명과 메시지 키/특정 파티션/동기-비동기 전송 (0) | 2021.12.02 |
| [Kafka] 카프카의 특징과 내부구조 (브로커, 프로듀서, 컨슈머, 파티션) (0) | 2021.10.27 |




댓글