Elasticsearch의 멀티테넌트 개념과 사용 방법
멀티테넌트의 개념
요즘 대부분의 IT 기업에서 프로젝트를 진행할때 클라우드 환경에서 서비스하는것을 기반으로 개발하는것이 일반적입니다. 클라우드 방식은은 규모의 경제 측면에서 봤을때 기존의 방식에 비해 비용절감을 할수있는 장점이 있습니다.
특히 클라우드 환경에서 멀티테넌트 아키텍쳐 개념이 중요한데 클라우드가 규모의 경제 측면에서 장점을 가질수 있도록 하는 가장 큰 이유이기 때문입니다. 테넌트란 특정 그룹의 단위를 나타내는 개념인데 회사, 부서, 팀 등 유형별로 나눈 그룹을 뜻합니다.
멀티테넌트는 여러개의 테넌트를 한곳에서 관리 하는것인데 기존에는 각 테넌트 별로 프로그램도 분리되고 서버도 분리 됬었지만 클라우드의 도입으로 모든 테넌트를 한곳에서 관리하는것이 멀티테넌트 의 목적입니다.
엘라스틱서치와 멀티 테넌트
클라우드 환경 기반의 프로젝트를 진행한다면 데이터 수집, 검색을 사용할때 엘라스틱서치를 주로 사용하게 됩니다. 엘라스틱 서치에서 멀티 테넌트를 사용하는 방법은 크게 두가지로 나눌수 있습니다.
- 각 테넌트별로 개별 인덱스 사용하기
- 하나의 인덱스에서 모든 테넌트 사용하기
엘라스틱서치의 데이터 저장 개념
두 방법은 인덱스를 어떻게 사용하느냐에 따라 구분되는데 인덱스(Index)는 엘라스틱서치의 데이터 저장단위입니다. 관계형 데이터베이스(RDMBS) 오라클이나 MariaDB의 데이터베이스 단위와 같은 개념으로 볼수있습니다.
엘라스틱서치 클러스터 환경에서 각 인덱스는 샤드(Shard) 라는 단위로 분리되어 관리됩니다. 샤드는 클러스터에 있는 노드들에 분산됩니다.
1. 각 테넌트 별로 인덱스 사용하기
- 장점 : 관리가 쉽고 데이터를 격리할수 있다.
- 단점 : 테넌트 개수만큼 인덱스가 늘어나므로 디스크 용량의 비용적인 문제가 생긴다.
테넌트마다 인덱스를 사용한다면 관리적인 측면과 데이터를 격리할수 있다는 점에서 장점이 있지만 비용적인 문제가 발생합니다. 새로운 테넌트가 추가될때마다 인덱스도 늘어나게 되고 그만큼 저장공간이 필요하게되는데 실제 테넌트가 사용하는 데이터를 제외하고도 인덱스가 생성될때 생성되는 기초 데이터의 용량도 계속 발생하기 때문입니다.
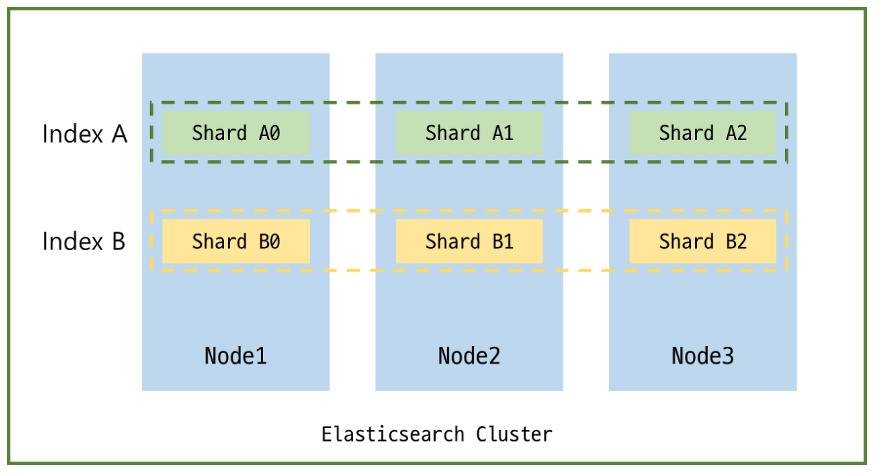
위 그림은 Elasticsearch 클러스터의 구성도를 간단하게 나타낸것입니다. 테넌트별로 인덱스가 증가하게 된다면 그만큼 샤드의 수도 증가하게 되는데 샤드의 증가는 메모리 사용량과 OS 자원 점유의 오버헤드와 연관이 있습니다. 샤드 내부에있는 루씬(Lucene) 인덱스가 오버헤드를 유발하기 때문입니다.
테넌트별로 인덱스를 사용해야 하는 경우는 테넌트별로 데이터 구조의 차이가 크거나 하나의 인덱스로 관리하기에 적합하지 않는경우에 사용할수 있습니다. 유의해야 할점은 테넌트가 생성될때마다 인덱스와 샤드가 계속 늘어나는데 한번 생성된 샤드는 수정이 불가능합니다.
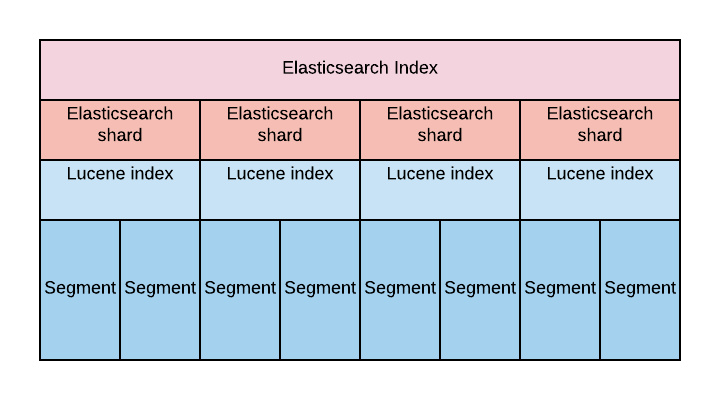
각 샤드 내부에 있는 루씬(Lucene)은 외부에 다른 인덱스나 샤드에 대한 정보를 알수없기 때문에 인덱스의 샤드 개수를 조정하거나 샤드를 수정하는것은 샤드 내부의 루씬 정보를 전부 업데이트 해야 한다는 뜻이기 때문에 샤드의 변경은 불가능합니다.
그래서 상황에 맞게 적절한 샤드의 개수를 정하는것이 중요합니다. 엘라스틱서치에서는 샤드 1개의 용량을 20GB ~ 40GB로 하는것을 권장합니다.
2. 하나의 인덱스에서 모든 테넌트 사용하기
모든 테넌트 데이터를 하나의 인덱스로 관리할때는 샤드와 도큐먼트에 활용방식에 따라 몇가지 방법으로 구분됩니다.
- 검색 필터(Filter)
- 커스텀 라우팅(Custom routing)
- 커스팀 라우팅과 인덱스 별명(Index alias)
1) 검색 필터, Filter
검색 필터 방식은 각기 다른 테넌트를 구별할수 있는 고유식별 id를 지정하고 해당 id를 필터링하여 테넌트별 데이터를 관리하는 방식입니다. 엘라스틱서치의 기본 검색 알고리즘은 검색결과에 점수(score)를 부여하고 검색 내용과 일치하는 수준에 따라 응답하지만 필터는 점수와 상관없이 정확하게 일치하는 데이터만 반환합니다.
자주 사용하는 필터는 캐시(Cache)에 저장되어 처리속도를 올려주는데 캐시에 값이 적재되는 과정에서 단일 테넌트에 비해 속도저하 현상이 발생할수 있다는 단점이 있습니다.
2) 커스텀 라우팅(Custom Routing)
엘라스틱서치의 인덱스는 도큐먼트라는 데이터의 집합으로 이루어져 있고 RDBMS에서 row와 같은 개념입니다. 커스텀 라우팅 방식은 도큐먼트가 인덱스에 저장될때 특정 샤드에 저장되도록 지정하는 방법입니다. 테넌트마다 별도의 라우팅값을 설정하여 샤드를 구분하는것인데 필터방식과 다르게 테넌트별로 독립된 데이터 공간과 검색결과를 가지므로 성능상 유리합니다.
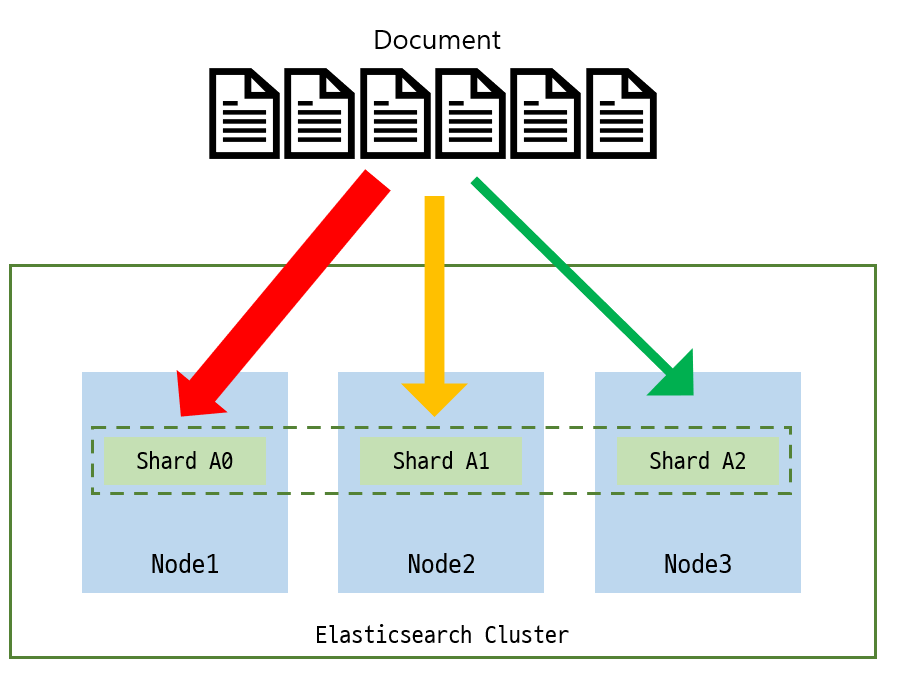
하지만 테넌트마다 데이터의 사용량이 다른만큼 샤드의 용량이 달라지는데 엘라스틱서치 클러스터 개념에서 보면 특정 테넌트의 데이터 사용량이 너무많으면 해당 샤드가 위치해있는 노드에 부담이 커질수 있습니다. 이때는 샤드의 하위집합을 구성하여 테넌트의 데이터를 여러개의 샤드에 분배하는 방법이 있습니다.
만약 테넌트의 개수보다 샤드의 개수가 적다면 하나의 샤드에 두개이상의 테넌트 데이터를 넣는 방법도 있습니다. 이 방법은 필터를 사용해서 검색하므로 샤드와 테넌트가 1:1 일때 보다는 성능이 떨어지지만 검색범위가 특정 샤드로 한정된다는 점에서는 단순 필터방식 보다는 유리한 방식입니다.
3) 커스텀 라우팅 & 인덱스 별명
인덱스 별명이란 인덱스 이름을 참조하기 위한 개념인데 하나 이상의 인덱스를 참조하기 위한 용도로 사용됩니다. 다수의 인덱스를 대상으로 검색을 수행하거나 기존 인덱스를 수정하는 경우, 새로운 인덱스로 변경하는 작업을 쉽게 할수 있습니다. 서비스 운영중에 인덱스에 문제가 발생할경우 새로운 인덱스를 생성한후 인덱스 별명이 참조하는 참조하는 인덱스를 변경하기만 하면 서비스 중단 시간을 최소화 하여 운영할수 있는 장점이 있습니다.
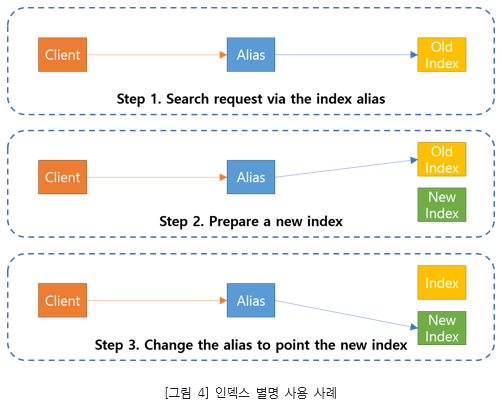
커스텀 라우팅으로 테넌트별 지정된 샤드를 사용할때 필터를 사용하여 인덱스 별명을 활용할수 있습니다. 필터링된 인덱스 별명은 라우팅 설정과 함께 인덱스에서도 테넌트 식별자로 사용할 필드를 대상으로 필터링 할수 있습니다.
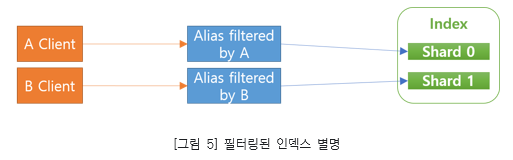
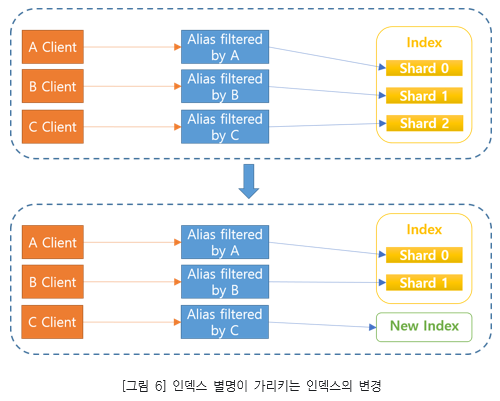
만약 특정 테넌트들의 데이터 유입이 늘어나서 엘라스틱서치 클러스터의 노드가 불균형해진다면 필터링된 인덱스 별명을 사용하여 해당 테넌트를 별도의 인덱스로 분리시키는 방법을 사용해볼수 있습니다.
아래 그림에서 C 클라이언트가 저장하는 데이터의 양이 늘어나서 하나의 인덱스로 관리하기 어려워진다면 필터링된 인덱스 별명을 활용해 별도의 인덱스로 분리하는 방법이 있습니다. 엘라스틱서치에서 alias 설정만 변경해주면 되기 때문에 C 클라이언트 입장에서는 별도의 설정 변경없이 서비스를 운영할수 있다는 장점이 있습니다.
멀티테넌트 운영 방법 선택하기
어느것이 정답이다 라고 할수는 없겠지만 관리해야 하는 테넌트가 지속적으로 늘어나고 데이터의 확장을 용이하게 하기 위해서는 테넌트 기반 라우팅 방식이 좋다고 생각합니다. 테넌트와 인덱스를 1:1로 관리하는 방식은 테넌트의 데이터가 늘어날경우 확장측면에서 불리하지만 테넌트 라우팅 방식은 단일 인덱스 내에서 테넌트별 데이터를 논리적으로 구분할수 있기 때문에 데이터가 늘어나서 확장하게 되더라도 쉽게 관리할수 있기 때문입니다.
해외 기술사이트에서도 찾아본결과 인덱스당 테넌트를 관리하는것보다는 테넌트에 대한 라우팅 방식을 사용하는것이 장기적으로 유리한 방법이라고 많이 설명되있습니다. 라우팅 방식으로 테넌트별 샤드를 관리하다가 특정 고객의 데이터가 단일 인덱스에서 관리하기에 너무 커진다면 해당 테넌트는 별도의 인덱스로 분리하여 관리하고 기존 인덱스는 계속하여 여러 테넌트가 공유하는 방법을 설명하고 있습니다.
참고사이트
https://techblog.bozho.net/elasticsearch-multitenancy-with-routing/
https://stackoverflow.com/questions/41868056/multi-tenancy-in-elastic-search
'클라우드' 카테고리의 다른 글
| Vault 암호화 관리 시스템 개념, Transit Secret Engine 예제 (0) | 2024.03.25 |
|---|---|
| Rancher 쿠버네티스 클러스터 생성과 관리 (1) | 2024.01.30 |


댓글